Collaborating with Github
Overview
Teaching: 30 min
Exercises: 60 minQuestions
How can I develop and collaborate on code with another scientist?
How can I give access to my code to another collaborator?
How can I keep code synchronised with another scientist?
How can I solve conflicts that arise from that collaboration?
What are Github
Objectives
Be able to create a new repository and share it with another scientist.
Be able to work together on a R script through RStudio and Github integration.
Understand how to make issues and explore the history of a repository.
Table of contents
Introduction
The collaborative power of GitHub and RStudio is really game changing. So far we’ve been collaborating with our most important collaborator: ourselves. But, we are lucky that in science we have so many other collaborators, so let’s learn how to accelerate our collaborations with them through GitHub!
We are going to teach you the simplest way to collaborate with someone, which is for both of you to have privileges to edit and add files to a repository. GitHub is built for software developer teams but we believe that it can also be beneficial to scientists.
We will do this all with a partner, and we’ll walk through some things all together, and then give you a chance to work with your collaborator on your own.
Pair up and work collaboratively
- Make groups of two scientists. They will collaborate through Github.
- Decide who will own the Github repository: this will be the “owner” also referred to as Partner 1.
- The other scientist will be called the “collaborator” also referred to as Partner 2.
- Please write your role on a sticky note and place it on your laptop to remember who you are!
Owner (Partner 1) setup
Create a Github repository
The repository “owner” will connect to Github and create a repository called first-collaboration. We will do this in the same way that we did in the “Version control with git and Github” episode.
Create a gh-pages branch
We aren’t going to talk about branches very much, but they are a powerful feature of git and GitHub. I think of it as creating a copy of your work that becomes a parallel universe that you can modify safely because it’s not affecting your original work. And then you can choose to merge the universes back together if and when you want.
By default, when you create a new repo you begin with one branch, and it is named master. When you create new branches, you can name them whatever you want. However, if you name one gh-pages (all lowercase, with a - and no spaces), this will let you create a website. And that’s our plan. So, owner/partner 1, please do this to create a gh-pages branch:
On the homepage for your repo on GitHub.com, click the button that says “Branch:master”. Here, you can switch to another branch (right now there aren’t any others besides master), or create one by typing a new name.
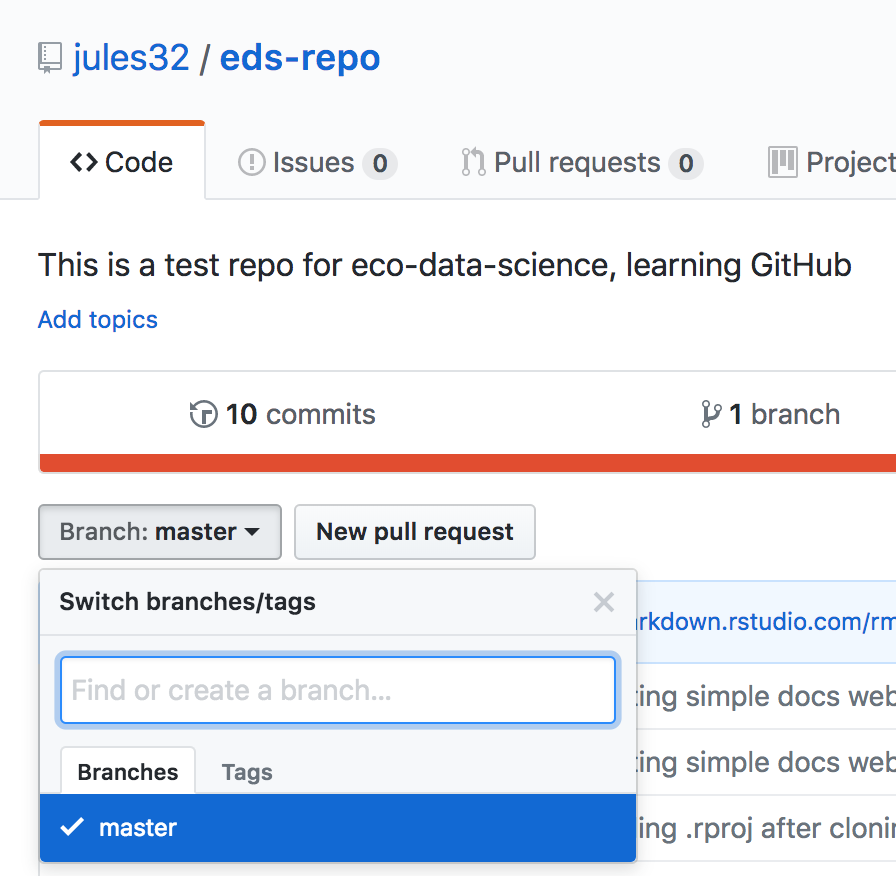
Let’s type gh-pages.
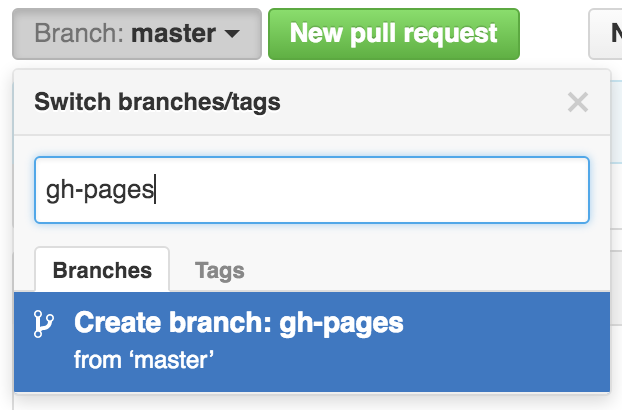
Let’s also change gh-pages to the default branch and delete the master branch: this will be a one-time-only thing that we do here:
First click to control branches:
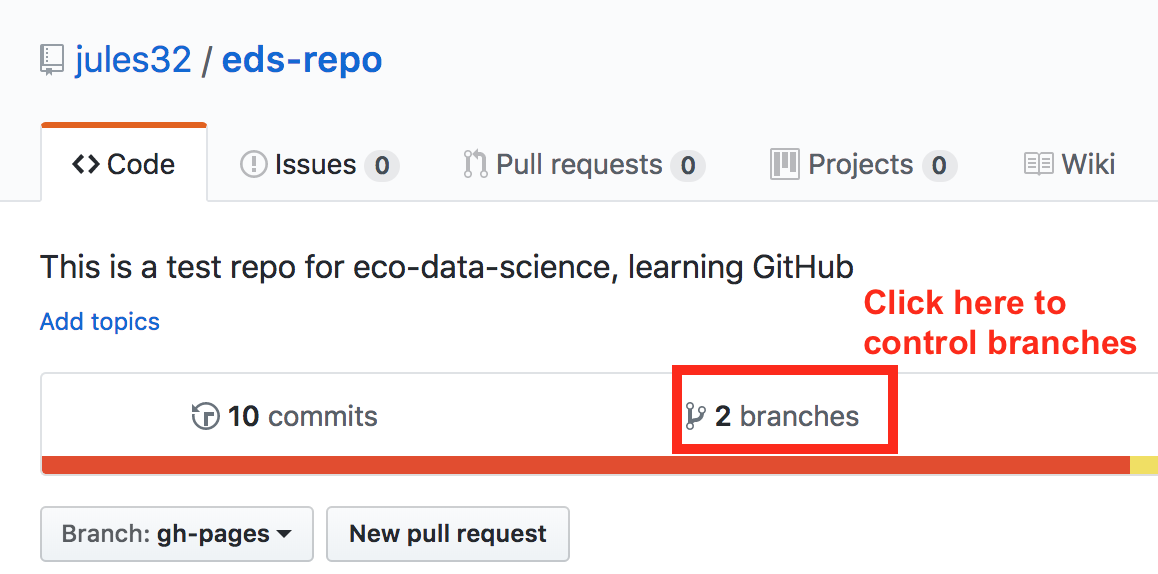
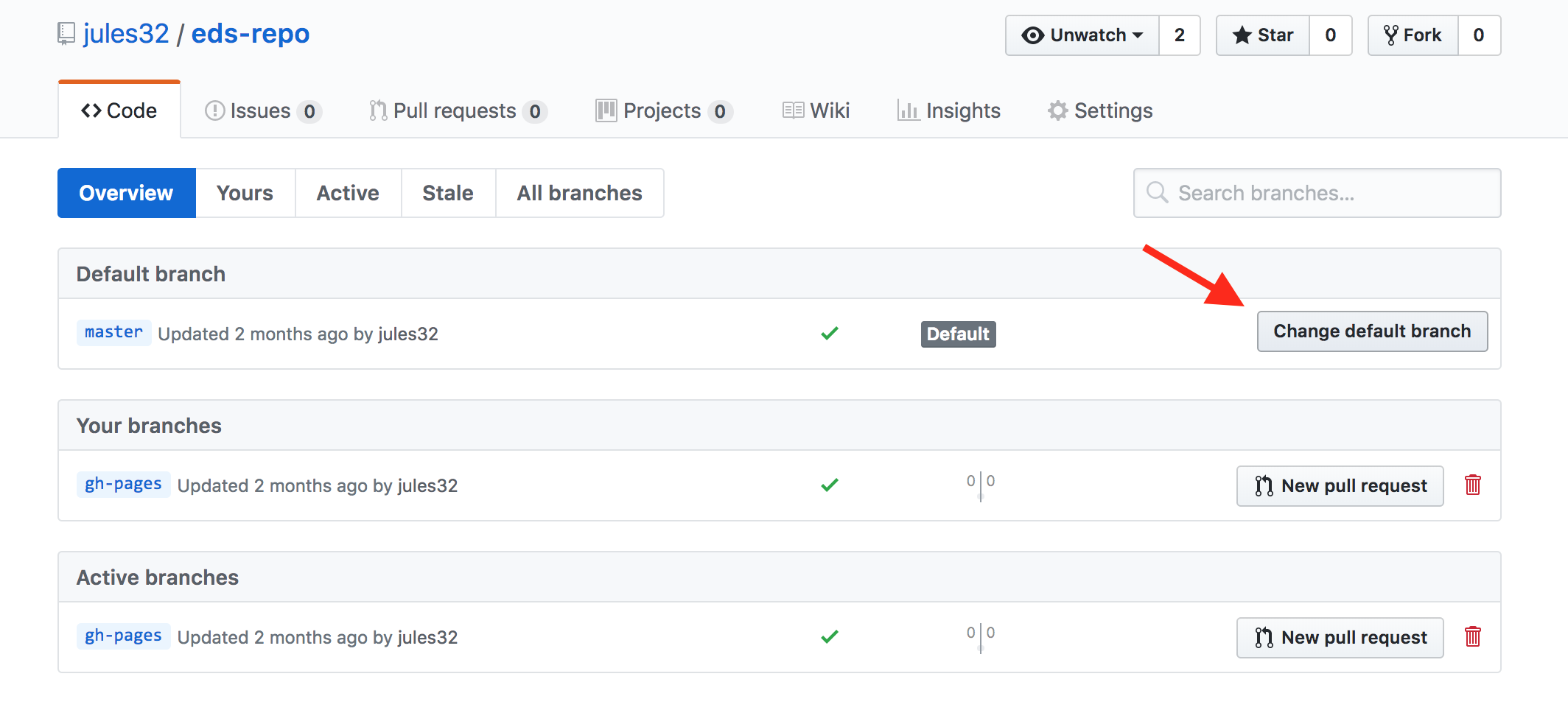
And then click to change the default branch to gh-pages. I like to then delete the master branch when it has the little red trash can next to it. It will make you confirm that you really want to delete it, which I do!
Give your collaborator administration privileges (Partner 1 and 2)
Now, Partner 1, go into Settings > Collaborators > enter Partner 2’s (your collaborator’s) username.
Partner 2 then needs to check their email and accept as a collaborator. Notice that your collaborator has “Push access to the repository” (highlighted below):

Clone to a new Rproject (Owner Partner 1)
Now let’s have Partner 1 clone the repository to their local computer. We’ll do this through RStudio like we did before (see the “Version control with git and Github:Clone your repository using RStudio” episode section. But, we’ll do this with a final additional step before hitting the “Create Project”: we will select “Open in a new Session”.

Opening this Project in a new Session opens up a new world of awesomeness from RStudio. Having different RStudio project sessions allows you to keep your work separate and organized. So you can collaborate with this collaborator on this repository while also working on your other repository from this morning. I tend to have a lot of projects going at one time:
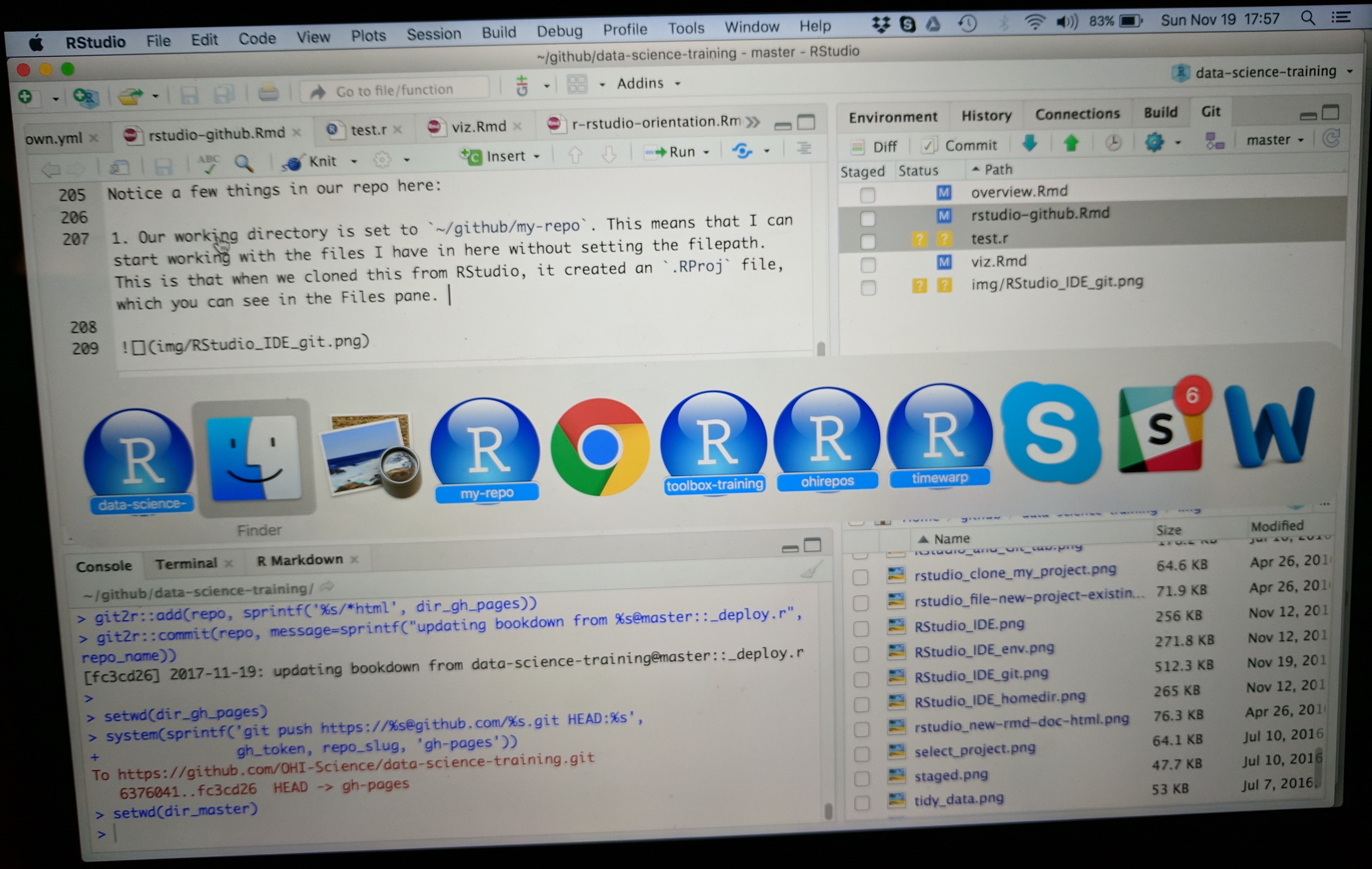
Have a look in your git tab.
Like we saw earlier, when you first clone a repo through RStudio, RStudio will add an .Rproj file to your repo. And if you didn’t add a .gitignore file when you originally created the repo on GitHub.com, RStudio will also add this for you. So, Partner 1, let’s go ahead and sync this back to GitHub.com.
Remember:

Let’s confirm that this was synced by looking at GitHub.com again. You may have to refresh the page, but you should see this commit where you added the .Rproj file.
Collaborator (Partner 2) part
Clone to a new Rproject (Partner 2)
Now it’s Partner 2’s turn! Partner 2, clone this repository following the same steps that Partner 1 just did. When you clone it, RStudio should not create any new files — why? Partner 1 already created and pushed the .Rproj and .gitignore files so they already exist in the repo.
Discussion point
Question: When you clone it, RStudio should not create any new files — why?
Solution
Partner 1 already created and pushed the
.Rprojand.gitignorefiles so they already exist in the repo.
Edit a file and sync (Partner 2)
Let’s have Partner 2 add some information to the README.md. Let’s have them write:
Collaborators:
- Partner 2's name
When we save the README.md, And now let’s sync back to GitHub.
When we inspect on GitHub.com, click to view all the commits, you’ll see commits logged from both Partner 1 and 2!
Discussion point
Questions:
- Would you be able to clone a repository that you are not a collaborator on?
- What do you think would happen? Try it!
- Can you sync back?
Solution
- Yes, you can clone a repository that is publicly available.
- If you try to clone it on your local machine, it does work.
- Unfortunately, if you don’t have write permissions, you cannot contribute. You would have to ask for write/push writes.
State of the Repository
OK, so where do things stand right now? GitHub.com has the most recent versions of all the repository’s files. Partner 2 also has these most recent versions locally. How about Partner 1?
Partner 1 does not have the most recent versions of everything on their computer!.
Discussion point
Question: How can we change that? Or how could we even check?
Solution
PULL !
Let’s have Partner 1 go back to RStudio and Pull. If their files aren’t up-to-date, this will pull the most recent versions to their local computer. And if they already did have the most recent versions? Well, pulling doesn’t cost anything (other than an internet connection), so if everything is up-to-date, pulling is fine too.
I recommend pulling every time you come back to a collaborative repository. Whether you haven’t opened RStudio in a month or you’ve just been away for a lunch break, pull. It might not be necessary, but it can save a lot of heartache later.
Merge conflicts
What kind of heartache are we talking about? Let’s explore.
Stop and watch me create and solve a merge conflict with my Partner 2, and then you will have time to recreate this with your partner.
Within a file, GitHub tracks changes line-by-line. So you can also have collaborators working on different lines within the same file and GitHub will be able to weave those changes into each other – that’s it’s job! It’s when you have collaborators working on the same lines within the same file that you can have merge conflicts. Merge conflicts can be frustrating, but they are actually trying to help you (kind of like R’s error messages). They occur when GitHub can’t make a decision about what should be on a particular line and needs a human (you) to decide. And this is good – you don’t want GitHub to decide for you, it’s important that you make that decision.
Me = partner 1. My co-instructor = partner 2.
Here’s what me and my collaborator are going to do:
- My collaborator and me are first going to pull.
- Then, my collaborator and me navigate to the README file within RStudio.
- My collaborator and me are going to write something in the same file on the same line. We are going to write something in the README file on line 7: for instance, “I prefer R” and “I prefer Python”.
- Save the README file.
- My collaborator is going to pull, stage, commit and push.
- When my collaborator is done, I am going to pull.
- Error! Merge conflict!

I am not allowed to to pull since GitHub is protecting me because if I did successfully pull, my work would be overwritten by whatever my collaborator had written.
GitHub is going to make a human (me in this case) decide. GitHub says, “either commit this work first, or stash it”. Stashing means “ (“save a copy of the README in another folder somewhere outside of this GitHub repository”).
Let’s follow their advice and have me to commit first. Great. Now let’s pull again.
Still not happy!
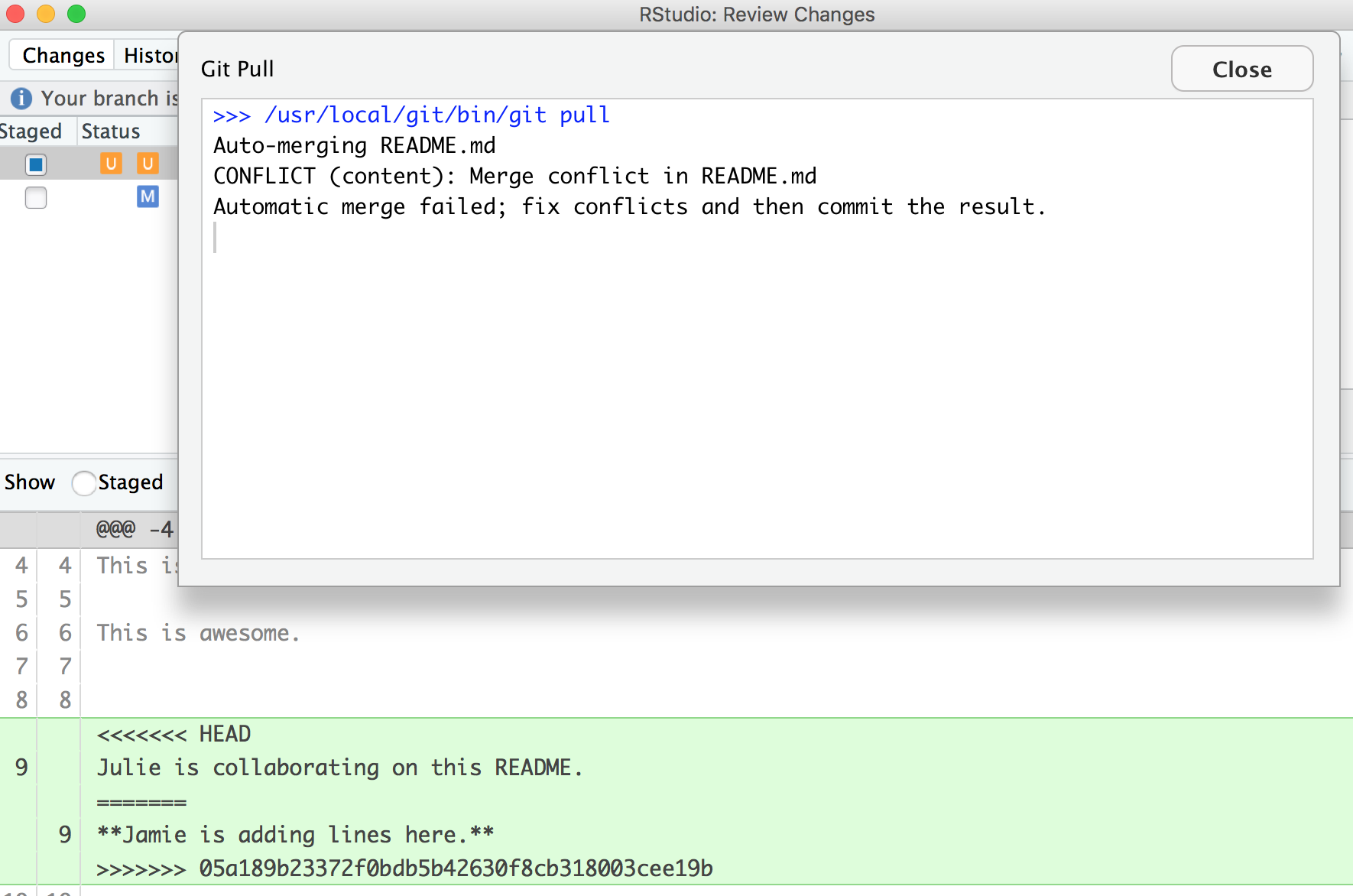
OK, actually, we’re just moving along this same problem that we know that we’ve created: Both me and my collaborator have both added new information to the same line. You can see that the pop-up box is saying that there is a CONFLICT and the merge has not happened. OK. We can close that window and inspect.
Notice that in the git tab, there are orange Us; this means that there is an unresolved conflict, and it is not staged with a check anymore because modifications have occurred to the file since it has been staged.
Let’s look at the README file itself. We got a preview in the diff pane that there is some new text going on in our README file:
<<<<<<< HEAD
Julie is collaborating on this README.
=======
**Jamie is adding lines here.**
>>>>>>> 05a189b23372f0bdb5b42630f8cb318003cee19b
In this example, I am Jamie and my collaborator is Julie. GitHub is displaying the line that Julie wrote and the line Jamie wrote separated by =======. So these are the two choices that Partner 2 has to decide between, which one do you want to keep? Where where does this decision start and end? The lines are bounded by <<<<<<<HEAD and >>>>>>>long commit identifier.
So, to resolve this merge conflict, my collaborator has to chose, and delete everything except the line they want. So, they will delete the <<<<<<HEAD, =====, >>>>long commit identifier and one of the lines that they don’t want to keep.
Do that, and let’s try again. In this example, we’ve kept my (Jamie’s) line:
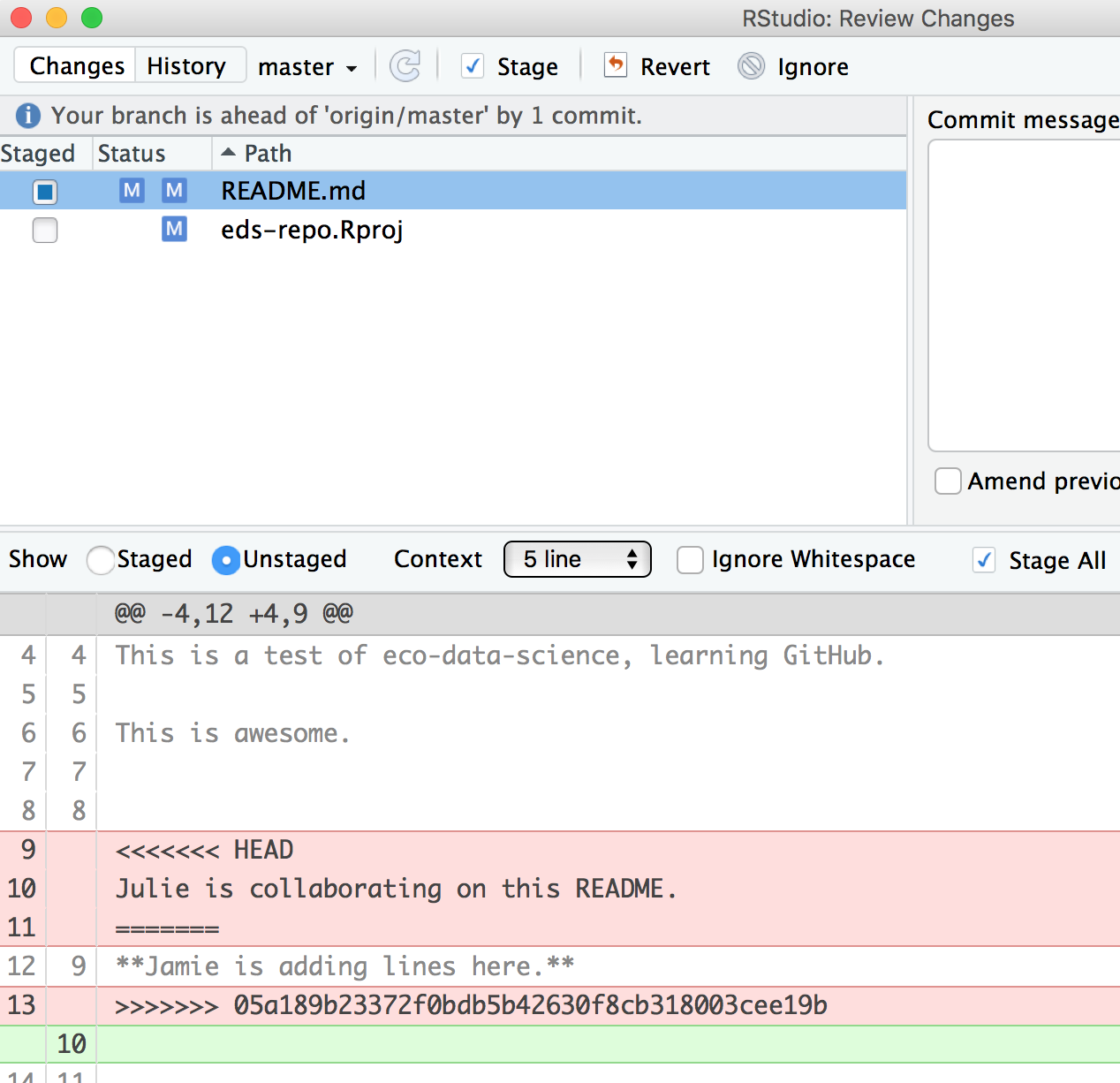
Then be I need to stage and write a commit message. I often write “resolving merge conflict” or something so I know what I was up to. When I stage the file, notice how now my edits look like a simple line replacement (compare with the image above before it was re-staged):

Your turn
Exercise
- Create a merge conflict with your partner, like we did in the example above.
- Try to fix it.
- Try other ways to get and solve merge conflicts. For example, when you get the following error message, try both ways (commit or stash. Stash means copy/move it somewhere else, for example, on your Desktop temporarily).
How do you avoid merge conflicts?
I’d say pull often, commit and sync often.
Also, talk with your collaborators. Even on a very collaborative project (e.g. a scientific publication), you are actually rarely working on the exact same file at any given time. And if you are, make sure you talk in-person or through chat applications (Slack, Gitter, Whatsapp, etc.).
But merge conflicts will occur and some of them will be heartbreaking and demoralizing. They happen to me when I collaborate with myself between my work computer and laptop. So protect yourself by pulling and syncing often!
Create your collaborative website
OK. Let’s have Partner 2 create a new RMarkdown file. Here’s what they will do:
- Pull!
- Create a new RMarkdown file and name it
index.Rmd. Make sure it’s all lowercase, and namedindex.Rmd. This will be the homepage for our website! - Maybe change the title inside the Rmd, call it “Our website”
- Knit!
- Save and sync your .Rmd and your .html files: pull, stage, commit, pull, push.
- Go to GitHub.com and go to your rendered website! Where is it? Figure out your website’s url from your github repo’s url. For example:
- my github repo: https://github.com/jules32/collab-research
- my website url: https://jules32.github.io/collab-research/
- note that the url starts with my username.github.io
So cool! On websites, if something is called index.html, that defaults to the home page. So https://jules32.github.io/collab-research/ is the same as https://jules32.github.io/collab-research/index.html. If you name your RMarkdown file my_research.Rmd, the url will become https://jules32.github.io/collab-research/my_research.html.
Your turn
Exercise
Here is some collaborative analysis you can do on your own. We’ll be playing around > with airline flights data, so let’s get setup a bit.
- Person 1: clean up the README to say something about you two, the authors.
- Person 2: edit the
index.Rmdor create a new RMarkdown file: maybe add something about the authors, and knit it.- Both of you: sync to GitHub.com (pull, stage, commit, push).
- Both of you: once you’ve both synced (talk to each other about it!), pull again. You should see each others’ work on your computer.
- Person 1: in the RMarkdown file, add a bit of the plan. We’ll be exploring the
nycflights13dataset. This is data on flights departing New York City in 2013.- Person 2: in the README, add a bit of the plan.
- Both of you: sync
Explore on GitHub.com
Now, let’s look at the repo again on GitHub.com. You’ll see those new files appear, and the commit history has increased.
Commit History
You’ll see that the number of commits for the repo has increased, let’s have a look. You can see the history of both of you.
Blame
Now let’s look at a single file, starting with the README file. We’ve explored the “Raw” and “History” options in the top-right of the file, but we haven’t really explored the “Blame” option. Let’s look now. Blame shows you line-by-line who authored the most recent version of the file you see. This is super useful if you’re trying to understand logic; you know who to ask for questions or attribute credit.
Issues
Now let’s have a look at issues. This is a way you can communicate to others about plans for the repo, questions, etc. Note that issues are public if the repository is public.

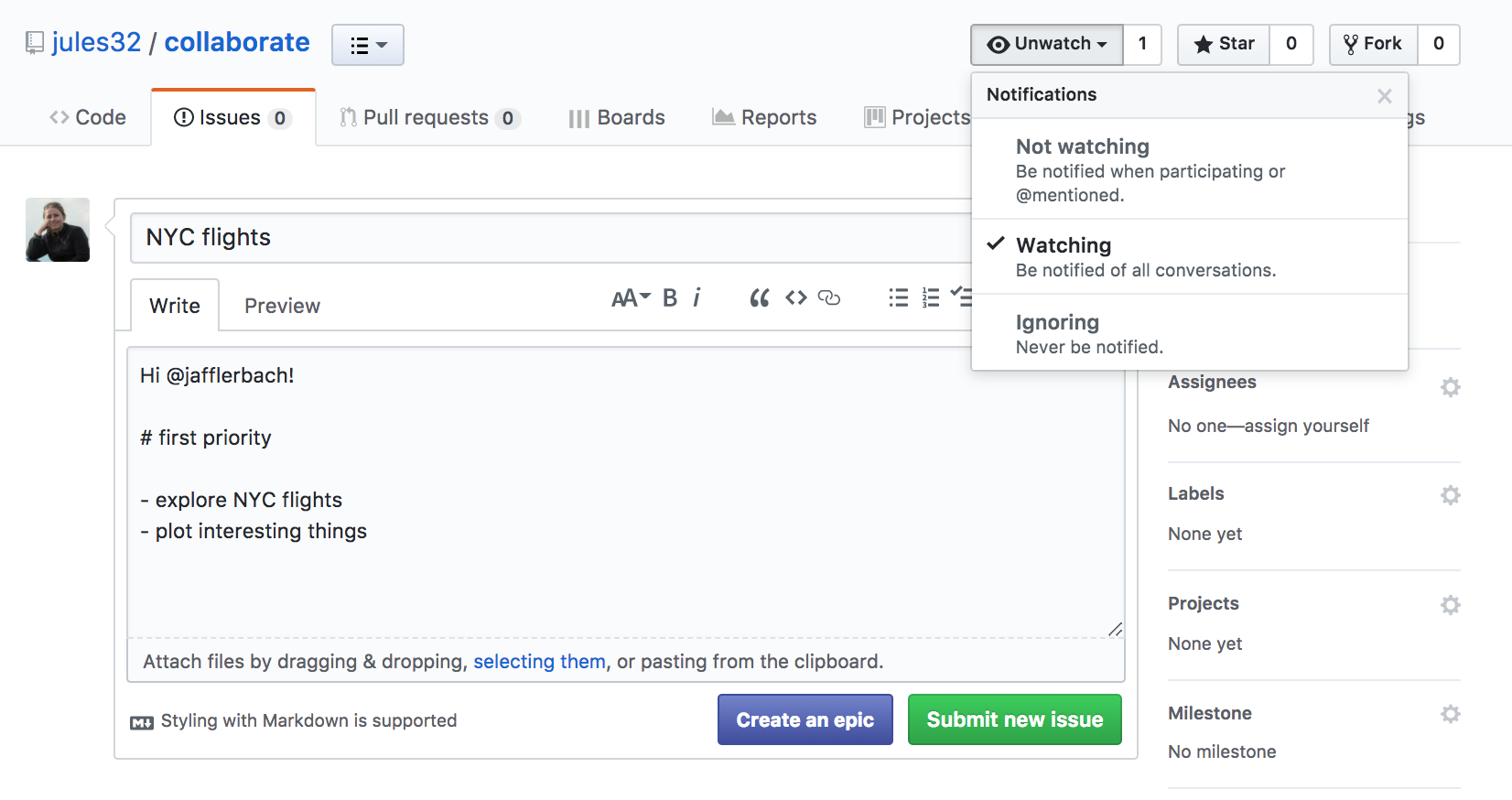
Let’s create a new issue with the title “NYC flights”.
In the text box, let’s write a note to our collaborator. You can use the Markdown syntax in this text box, which means all of your header and bullet formatting will come through. You can also select these options by clicking them just above the text box.
Let’s have one of you write something here. I’m going to write:
Hi @jafflerbach!
# first priority
- explore NYC flights
- plot interesting things
Note that I have my collaborator’s GitHub name with a @ symbol. This is going to email her directly so that she sees this issue. I can click the “Preview” button at the top left of the text box to see how this will look rendered in Markdown. It looks good!
Now let’s click submit new issue.
On the right side, there are a bunch of options for categorizing and organizing your issues. You and your collaborator may want to make some labels and timelines, depending on the project.
Another feature about issues is whether you want any notifications to this repository. Click where it says “Unwatch” up at the top. You’ll see three options: “Not watching”, “Watching”, and “Ignoring”. By default, you are watching these issues because you are a collaborator to the repository. But if you stop being a big contributor to this project, you may want to switch to “Not watching”. Or, you may want to ask an outside person to watch the issues. Or you may want to watch another repo yourself!
Let’s have Person 2 respond to the issue affirming the plan.
NYC flights exploration
Let’s continue this workflow with your collaborator, syncing to GitHub often and practicing what we’ve learned so far. We will get started together and then you and your collaborator will work on your own.
Here’s what we’ll be doing (from R for Data Science’s Transform Chapter):
Data: You will be exploring a dataset on flights departing New York City in 2013. These data are actually in a package called nycflights13, so we can load them the way we would any other package.
Let’s have Person 1 write this in the RMarkdown document (Partner 2 just listen for a moment; we will sync this to you in a moment).
library(nycflights13) # install.packages('nycflights13')
library(tidyverse)
This data frame contains all flights that departed from New York City in 2013. The data comes from the US Bureau of Transportation Statistics, and is documented in ?flights.
flights
Let’s select all flights on January 1st with:
filter(flights, month == 1, day == 1)
To use filtering effectively, you have to know how to select the observations that you want using the comparison operators. R provides the standard suite: >, >=, <, <=, != (not equal), and == (equal). We learned these operations yesterday. But there are a few others to learn as well.
Sync
Sync this RMarkdown back to GitHub so that your collaborator has access to all these notes.
Partner 2 pull
Now is the time to pull!
Partner 2 will continue with the following notes and instructions:
Logical operators
Multiple arguments to filter() are combined with “and”: every expression must be true in order for a row to be included in the output. For other types of combinations, you’ll need to use Boolean operators yourself:
&is “and”|is “or”!is “not”
Let’s have a look:
The following code finds all flights that departed in November or December:
filter(flights, month == 11 | month == 12)
The order of operations doesn’t work like English. You can’t write filter(flights, month == 11 | 12), which you might literally translate into “finds all flights that departed in November or December”. Instead it finds all months that equal 11 | 12, an expression that evaluates to TRUE. In a numeric context (like here), TRUE becomes one, so this finds all flights in January, not November or December. This is quite confusing!
A useful short-hand for this problem is x %in% y. This will select every row where x is one of the values in y. We could use it to rewrite the code above:
nov_dec <- filter(flights, month %in% c(11, 12))
Sometimes you can simplify complicated subsetting by remembering De Morgan’s law: !(x & y) is the same as !x | !y, and !(x | y) is the same as !x & !y. For example, if you wanted to find flights that weren’t delayed (on arrival or departure) by more than two hours, you could use either of the following two filters:
filter(flights, !(arr_delay > 120 | dep_delay > 120))
filter(flights, arr_delay <= 120, dep_delay <= 120)
Whenever you start using complicated, multipart expressions in filter(), consider making them explicit variables instead. That makes it much easier to check your work.
Partner 2 sync
Once you have filtered the flights dataframe for flights, sync it to Github (add, commit and push).
Your turn
Based on what you’ve learned previously about data transformation, you’ll make a series of data transformation on the flights dataset. Some ideas:
- calculate the average flight delay.
- determine the longest flight distance.
- Your own question!
Exercise
Partner 1 will pull so that we all have the most current information. With your partner, transform and compute several metrics about the data. Partner 1 and 2, make sure you talk to each other and decide on who does what. Remember to make your commit messages useful! As you work, you may get merge conflicts. This is part of collaborating in GitHub; we will walk through and help you with these and also teach the whole group.
Key Points
Github allows you to synchronise work efforts and collaborate with other scientists on (R) code.
Github can be used to make custom website visible on the internet.
Merge conflicts can arise between you and yourself (different machines).
Merge conflicts arise when you collaborate and are a safe way to handle discordance.
Efficient collaboration on data analysis can be made using Github.